選擇完模型後,
接下來要進行「超參數調整」,
但是其實對模型的提升有限。
以上都是模型的「超參數」,
調整超參數會直接影響模型的訓練結果,
可以先用預設值,再慢慢調整。
窮舉法 (Grid Search)
直接指定超參數的組合範圍,每一組參數都訓練完成,再根據驗證集的結果選擇最佳參數。
隨機搜尋 (Random Search)
指定超參數的範圍,⽤均勻分布進⾏參數抽樣,⽤抽到的參數進⾏訓練,再根據驗證集的結果選擇最佳參數。
參考文章Scanning hyperspace: how to tune machine learning models,
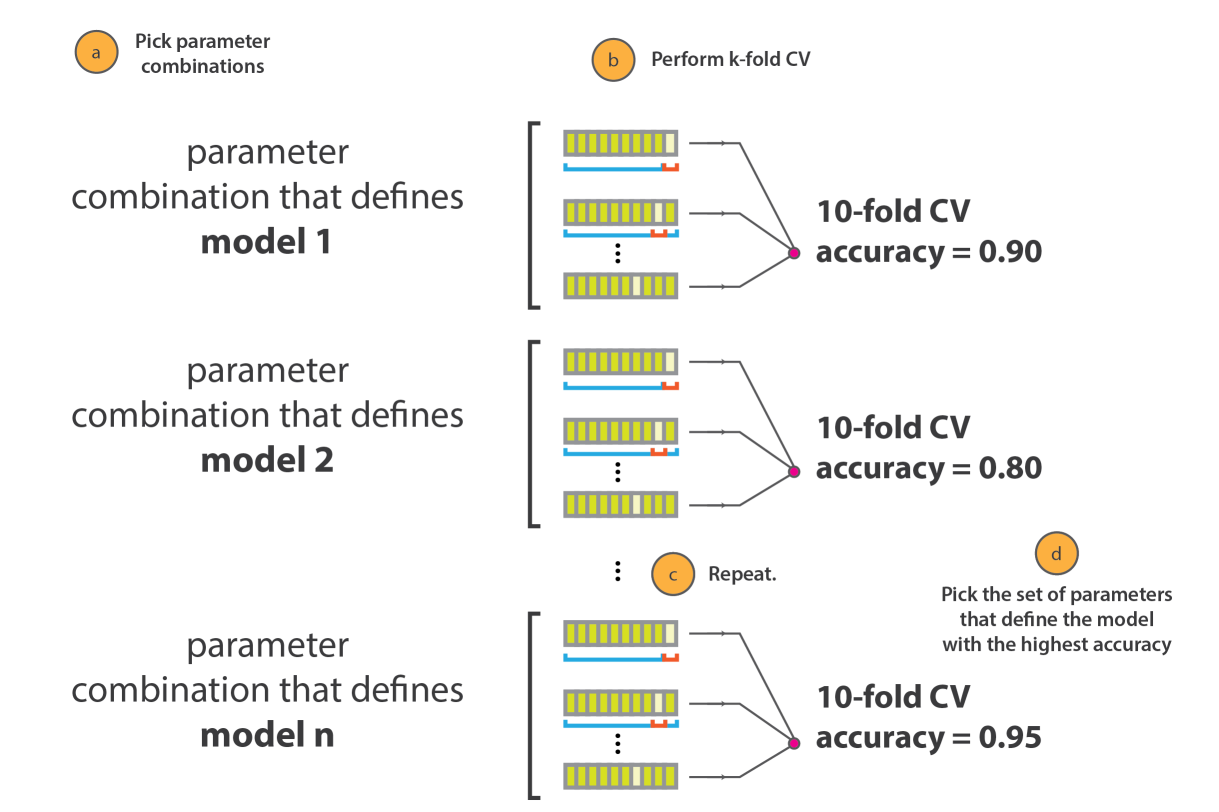
真正重要的還是先前的EDA和特徵工程,
超參數調整只能微幅下降loss,
所以不要花太多時間在此。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽